SEO · 2026-05-24
What Google’s AI Search Patents Reveal About SEO
Google AI Search patents show how AI Overviews may retrieve, verify, cite, and reuse web content — and what SEOs should do to become trusted source material.
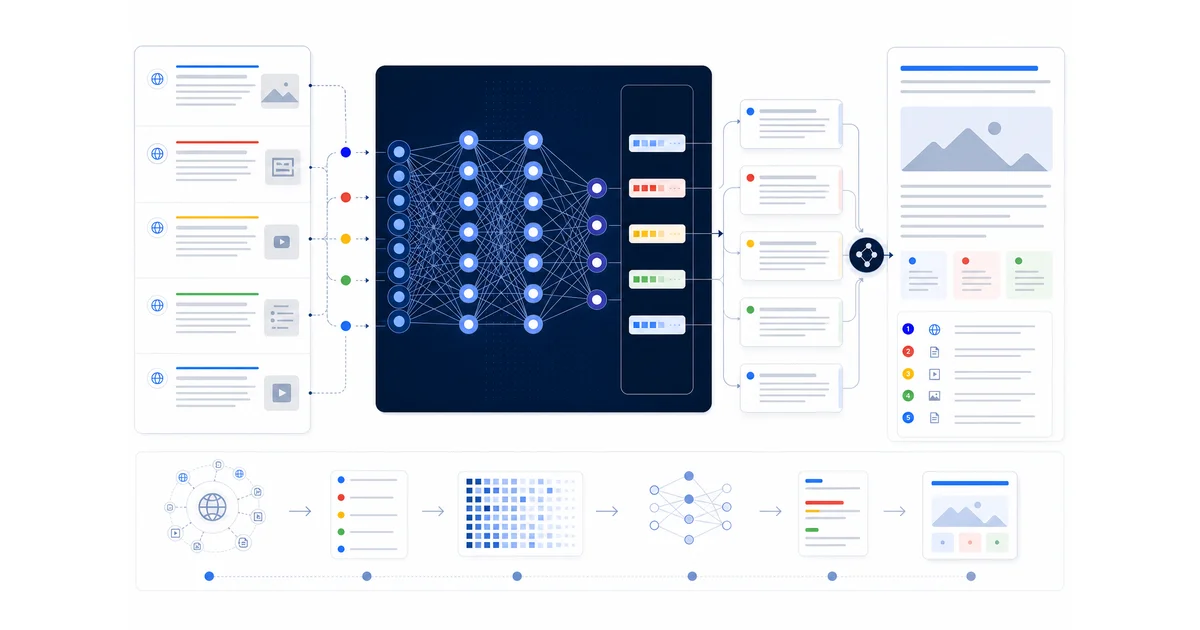
Abstract. Google’s recent AI Search patents suggest that the future of SEO is not just about ranking a page. It is about becoming trusted source material for generated answers. The patents describe a search architecture that retrieves documents, selects passages, generates synthetic queries, summarizes evidence with large language models, checks factual support, links claims to sources, and adapts across a user’s search session. If that is directionally right, the SEO job changes: build pages that can be found, extracted, trusted, cited, and reused by answer engines.
In my SEO and growth work, the pattern has been consistent: Google changes the surface — blue links, featured snippets, AI Overviews — and the incentives move underneath. The durable skill is understanding what Google needs to trust, then building pages and systems that make that trust easier. These patents are useful because they show the next version of that incentive system.
I do not read patents as gospel. A patent is not a production ranking-factor leak, and it does not prove that Google’s live AI Overviews work exactly as described. I read patents as blueprints for incentives. They show what problems Google is trying to solve, what system designs its researchers think are defensible, and which content structures are likely to become more valuable as search becomes more generative.
The simple takeaway is this: Google AI Search is not “ChatGPT in the SERP.” It looks more like a retrieval, grounding, summarization, personalization, and feedback system. That distinction matters. A chatbot can answer from model memory. AI Search needs to answer from the web, justify the answer, and decide which pages deserve to become evidence.
Research Question
The question I wanted to answer was practical:
Based on Google’s recent patents around search, LLMs, and generative answers, how should marketing teams, content engineers, and technical SEOs build websites for visibility in AI search engines?
My answer: optimize for source selection, not only for blue-link ranking. The best AI Search pages will be the pages an answer system can safely use as context: clear, structured, current, authoritative, linkable, and passage-level useful.
Patent Evidence: What Google Appears To Be Building
The following patents and patent applications are the core evidence base. I have focused on Google LLC patents from the last few years that relate to generative summaries, AI search, stateful chat, LLM grounding, factuality, query fan-out, custom corpora, and multimodal retrieval.
| Patent | What it describes | SEO implication |
|---|---|---|
| US11769017B1 / US11886828B1 | Generative summaries for search results using search result documents. | Your content must be extractable, trustworthy, fresh, and useful at the passage level. |
| US20240289407A1 | Search with stateful chat and a “generative companion.” | Search becomes multi-turn. Your content has to support journeys, not just isolated queries. |
| US20240289395A1 | Factuality of generated responses and attribution to sources. | Unsupported claims lose value. Corroborated claims become easier for AI systems to cite. |
| US12437016B2 | Fine-tuning LLMs using reinforcement learning with search engine feedback. | User behavior and search-conditioned outputs can influence future answer quality systems. |
| US20250117381A1 | Using LLMs to respond to multifaceted queries by generating subqueries. | Pages and topic clusters should answer related subquestions clearly and comprehensively. |
| US20240362093A1 | Query response using a custom corpus of documents. | Domain-specific corpora, product documentation, support docs, and knowledge bases become strategic assets. |
| US20240311405A1 | Dynamic selection among generative models with different computational costs. | Different query types may trigger different model paths, answer formats, and source needs. |
| US20240202796A1 | Search with machine-learned model-generated queries, including generated images used as search input. | Multimodal assets need semantic context: filenames, captions, alt text, surrounding copy, and schema. |
| WO2025072745A1 | Session-based user awareness in large language models. | AI answers can adapt to user expertise, prior engagement, and session context. |
| US11947923B1 | Multimedia content management for LLMs and generative models. | Images and videos are part of AI answers, but they need relevance, safety, and machine-readable meaning. |
| US12266065B1 | Visual indicators of generative model response details. | Future answers may visually connect generated instructions to objects, images, and interface elements. |
Some of these patents are central to the argument; others are supporting clues. The reinforcement-learning, model-selection, and visual-indicator patents matter because they point to the surrounding infrastructure: feedback loops, cost-aware model routing, and richer answer interfaces. They are not proof of specific ranking factors, but they help define the product constraints Google is likely optimizing around.
Finding 1: AI Search Starts With Retrieval, Not Pure Generation
The most important patent family is Generative summaries for search results. It describes using a large language model to generate a natural language summary in response to a query, but the summary is grounded in content from search result documents.
“Implementations disclosed herein are directed to at least selectively utilizing an LLM in generating an NL based summary to be rendered (e.g., audibly and/or graphically) in response to a query (e.g., a submitted query or an automatically generated query).”
That line alone is interesting, but the next part is the real SEO signal. The patent is not describing a model freelancing from memory. It is describing a model that processes additional content from retrieved documents:
“the additional content that is processed, using the LLM in generating the NL based summary to provide responsive to submission of a query includes: content from query-responsive search result document(s) that are responsive to the query; and/or content from other search result document(s) that are each responsive to a corresponding other query”
This means the page is not only competing to rank. It is competing to become context. The old SEO question was, “Can I rank?” The AI Search question is, “Can the system confidently use this passage to answer?”
What this changes
If a page is verbose, vague, stale, unsupported, or hard to parse, it may still rank as a blue link. But it is less attractive as source material for generated answers. AI Search needs passages that are direct, evidence-backed, and easy to attribute.
A practical page section should look like this:
<section id="ai-search-source-selection">
<h2>How AI search engines select sources</h2>
<p>AI search engines select sources by retrieving documents, extracting relevant passages, checking source quality, and using those passages to ground generated answers. Pages with clear headings, factual claims, current dates, and self-contained answer blocks are easier to cite.</p>
</section>That section is short, anchored, self-contained, and directly quotable. That is the shape of content I expect answer engines to prefer.
Finding 2: Source Selection Uses More Than Text Relevance
The same patent family also lists the kinds of measures that can influence which search result documents are selected. It explicitly separates query-dependent, query-independent, and user-dependent measures.
“Query-dependent measures for a query-responsive SRD can include, for example, a positional ranking of the query-responsive search result document and for the query, a selection rate of the query-responsive search result document and for the query, a locality measure that is based on an origination location of the query and a location corresponding to the query-responsive search result document, and/or a language measure that is based on a language of the query and a language corresponding to the query-responsive search result document.”
Then it describes query-independent signals:
“Query-independent measures for a query-responsive SRD can include, for example, a selection rate of the query-responsive search result document for multiple queries, a trustworthiness measure for the query-responsive search result document (e.g., one generated based on an author thereof, a domain thereof, and/or inbound link(s) thereto), an overall popularity measure for the query-responsive search result document, and/or a freshness measure that reflects recency of creation or updating of the query-responsive search result document.”
This is where a lot of AI Search advice gets too shallow. “Write helpful content” is not wrong, but it is incomplete. The page also has to look like a reliable source to a machine-selection system. That means the web page, author, domain, links, freshness, structure, and user fit all matter.
Practical implications
- Author clarity matters. Make the author, credentials, and organization easy to resolve.
- Freshness matters. Add visible “last updated” dates and keep volatile claims current.
- Entity consistency matters. Use the same names for products, people, categories, and concepts across the site.
- Local and language fit matter. For location-sensitive topics, build pages with real service areas, local examples, and clear regional context.
- Inbound authority still matters. The patents do not make links irrelevant. They put links into a broader trust system.
Finding 3: AI Search May Generate Its Own Related Queries
One of the biggest strategic shifts is query fan-out. AI Search does not have to answer only the literal words the user typed. It can generate additional queries, synthetic queries, subqueries, and follow-up directions.
The multifaceted query patent defines the problem clearly:
“a multifaceted query is multifaceted in that it relates to two or more facets (e.g., topics or problems).”
Then it describes the mechanism:
“implementations disclosed herein leverage an LLM or other generative model to generate a plurality of candidate subqueries for multifaceted NL based input”
The patent also says the system can “select a subset of the candidate subqueries utilizing one or more evaluation metrics,” including relatedness and diversity. That is the architecture of a research assistant, not a keyword matcher.
Example: “best CRM for small law firms”
A traditional SEO page might target the phrase “best CRM for small law firms.” An AI Search system might expand that into subqueries like:
- CRM pricing for small law firms
- legal intake workflow CRM
- CRM integrations with Clio and LawPay
- data privacy requirements for law firm CRM
- best CRM for solo attorneys vs small firms
- law firm CRM implementation checklist
- CRM alternatives for legal client management
If your page only has generic sales copy, you lose the fan-out. If your site has a topic cluster that answers each of those subqueries clearly, you become much more useful to the answer system.
A Reconstructed AI Search Pipeline
The patents do not give us production code. But they describe enough components to reconstruct a useful mental model. The flow below is not Google code. It is a simplified pseudocode version of the patent-described architecture.
def generate_ai_search_answer(query, user_state):
# 1. Interpret the user input and session context.
query_context = build_context(
query=query,
prior_queries=user_state.prior_queries,
clicked_documents=user_state.clicked_documents,
location=user_state.location,
language=user_state.language,
)
# 2. Generate related or synthetic queries.
synthetic_queries = generate_related_queries(query_context)
# 3. Retrieve candidate documents and passages.
candidates = search_index.retrieve(
queries=[query] + synthetic_queries
)
# 4. Select passages using source and context signals.
passages = select_passages(
candidates,
signals=[
"query_relevance",
"classic_ranking",
"trustworthiness",
"freshness",
"locality",
"language_match",
"user_context",
],
)
# 5. Generate a grounded natural language answer.
answer = llm.generate(
prompt=query,
grounding_context=passages,
)
# 6. Link claims back to supporting passages.
citations = verify_and_linkify(answer, passages)
return render_answer(answer, citations)If this is even directionally right, the SEO job changes. You are no longer only optimizing the document. You are optimizing the machine’s confidence in using pieces of the document.
Finding 4: Factuality And Attribution Are Core Product Problems
Google has a problem that old search did not have in the same way. A blue link can be wrong, but Google can say it merely ranked a source. A generated answer feels like Google is speaking. That raises the cost of hallucination.
The factuality patent says the quiet part out loud:
“Implementations relate to a system for training a generative large language model to produce factually-grounded answers with attribution to the source.”
It also describes why evidence matters:
“implementations disclose methods for discouraging generated content that recites a fact but where the fact is not supported by evidence.”
The same patent describes a model that identifies queries, obtains search results, and uses those results as model input:
“the system may include a large language model that not only takes a conversation context (or prompt context) as input, but also identifies a query/queries for the conversation context, obtains search results for the query/queries from a search engine, and provides the conversation context and the search results to the model as input.”
This is why citation-ready content matters. The model needs evidence. The rendering system needs attribution. The user needs enough source transparency to trust the generated answer.
What a citation-ready page looks like
- Claims are tied to visible evidence.
- Statistics include dates and sources.
- Definitions are precise and not buried.
- Comparisons use explicit criteria.
- The page separates facts, assumptions, and opinions.
- Each section can stand alone without requiring the reader to parse the whole page.
For technical teams, structured data can help reinforce those relationships. For example:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "What Google’s AI Search Patents Reveal About SEO",
"author": {
"@type": "Person",
"name": "Shaun McQuaker",
"url": "https://www.shaunmcquaker.com/resume"
},
"publisher": {
"@type": "Organization",
"name": "ShaunMcQuaker.com"
},
"datePublished": "2026-05-24",
"dateModified": "2026-05-24",
"about": [
"Google AI Search",
"AI Overviews SEO",
"large language models",
"answer engine optimization"
]
}Schema is not magic. It will not rescue weak content. But it helps machines understand the entity graph around the page: who wrote it, what it is about, when it changed, and which concepts it covers.
Finding 5: Search Becomes Stateful
Traditional search treats many queries as isolated events. AI Search is moving toward sessions. Google’s stateful chat patent frames this as a generative companion layered on top of search.
Implementations are described herein for augmenting a traditional search session with stateful chat—via what will be referred to as a “generative companion”—to facilitate more interactive searching.
The patent explains that the system can maintain a state across turns:
“maintaining and updating a contextual state of a user across multiple turns of a chat search session”
This changes how we should think about content architecture. If the user is researching a complex topic, Google may know that the current query is a follow-up to prior searches. It may know what the user clicked, what level of detail they need, and which part of the task they are trying to complete.
SEO implication: build journeys, not isolated pages
A good AI Search content system should have connected pages for different stages:
- Beginner explanation: what the topic is and why it matters.
- Evaluation: comparisons, pros/cons, criteria, alternatives.
- Implementation: steps, checklists, templates, technical details.
- Troubleshooting: common problems and fixes.
- Advanced optimization: edge cases, benchmarks, automation, trade-offs.
Internal links should use descriptive anchors. Do not link with “click here.” Link with “CRM implementation checklist,” “pricing comparison,” or “data privacy requirements.” Those anchors help both users and machines understand the journey.
Finding 6: User Expertise May Influence The Answer
Another patent, Session-based user awareness in large language models, deals with how an LLM can infer what a user does or does not understand based on engagement with the output.
“LLMs do not know the level of a user’s knowledge or expertise; accordingly, the LLM may provide an answer that is too complex for a user’s knowledge level.”
The patent describes engagement signals such as mouse movement, gaze, and looking up a word. It even gives an example where the model can remember that a user needed a definition:
the input to the LLM can include token(s) indicating that the user needed a definition for the term “fiduciary”
For content strategy, this argues for layered explanations. A single page can support multiple levels of expertise if it is structured well:
- Start with a simple answer.
- Define key terms.
- Then add deeper technical detail.
- Use examples to bridge the gap.
- Link to advanced material instead of forcing every reader through it.
This is not dumbing content down. It is making the page usable by more retrieval contexts.
Finding 7: Custom Corpora And Documentation Become More Valuable
The custom corpus patent is important for companies with product docs, help centers, developer documentation, research archives, or internal knowledge bases. It describes an LLM generating API queries to external applications, receiving relevant documents or embeddings, and conditioning the response on that corpus.
“Implementations disclosed herein are directed to at least utilizing a custom corpus of documents to condition an LLM when generating a response to a user query”
The same patent explains the API-query flow:
“the LLM processes a received user query to generate one or more API queries for one or more external applications that each has access to a respective custom corpus of documents.”
For software companies, this is a major clue. Your public docs and support content are not only customer-support assets. They are AI-discovery infrastructure.
What to do with documentation
- Give every feature a stable URL.
- Make docs crawlable where possible.
- Use consistent terminology between marketing pages, docs, release notes, and support articles.
- Add examples, error messages, API parameters, and troubleshooting paths.
- Use canonical pages for duplicated support answers.
- Keep changelogs and deprecation notices current.
The companies that win in AI Search will not only have better blog posts. They will have better corpora.
Finding 8: Multimodal Search Needs Machine-Readable Media
Google’s patents also point toward search becoming more visual and multimodal. The machine-learned model-generated queries patent describes generated images or datasets being used as search inputs.
“the present disclosure is directed to generating content (e.g., images) based on a user request (e.g., a prompt input) to provide a visualization of a requested item that can then be searched to provide a visually informed and directed search.”
The multimedia management patent is also relevant because it describes LLM responses that can include images, video clips, audio clips, GIFs, and other media:
“the multimedia content described herein can include multimedia content items, such as images, video clips, audio clips, gifs, and/or any other multimedia content that is suitable for being rendered at the client device 110.”
For SEO teams, the message is clear: images and videos need semantic support. A beautiful image with no useful filename, no alt text, no caption, and no surrounding explanatory copy is less useful to a multimodal retrieval system.
Multimodal checklist
- Use original diagrams and screenshots where possible.
- Add descriptive filenames.
- Write alt text that explains the object or concept.
- Use captions that state why the image matters.
- Surround images with relevant explanatory text.
- Add
ImageObjectorVideoObjectschema where useful. - Provide transcripts for video and audio.
The Content Engineering Playbook For AI Search
Here is the operational version. If I were rebuilding a site for AI Search visibility, this is the checklist I would use.
1. Write answer-first sections
Each important section should answer one question directly. The first paragraph under the heading should be quotable without requiring the rest of the page.
Weak: “In today’s fast-paced world, choosing the right CRM can be difficult.”
Better: “The best CRM for a small law firm is the one that handles intake, conflict checks, matter notes, billing handoff, and client follow-up without forcing staff to duplicate data across systems.”
2. Build around query clusters
Do not create one page per keyword variation. Create a topic map:
- Main guide
- Comparison page
- Implementation checklist
- Pricing guide
- Alternatives page
- Use-case pages
- FAQ / troubleshooting pages
The objective is to cover the fan-out. If Google decomposes the query, your site should have the answers.
3. Make every claim supportable
AI answers need evidence. Give them evidence. Use primary sources, original data, dates, tables, and explicit definitions. Avoid vague superlatives.
Weak: “We are the leading AI analytics platform.”
Better: “Our platform tracks daily Google search volume for individual keywords across markets and stores the historical series for trend analysis.”
4. Add stable section anchors
Generated answers may cite a page, but the ideal citation is a precise section. Add IDs to sections and keep them stable.
<h2 id="implementation-checklist">Implementation checklist</h2>
<ol>
<li>Define the primary query the section answers.</li>
<li>Write a direct answer in the first paragraph.</li>
<li>Add evidence, examples, and source links.</li>
<li>Link to related subtopics with descriptive anchor text.</li>
</ol>5. Use tables for decision content
Tables are useful because they make criteria explicit. AI systems can extract them, users can scan them, and editors can keep them updated.
| Content type | Why AI Search likes it | Example |
|---|---|---|
| Definition block | Easy to quote and attribute | “What is answer engine optimization?” |
| Comparison table | Maps well to multifaceted queries | CRM A vs CRM B vs CRM C |
| Checklist | Supports task completion | Technical SEO launch checklist |
| FAQ | Covers follow-up questions | Pricing, implementation, risks |
| Original data | Creates unique source value | Benchmark, survey, crawl study |
6. Treat docs as SEO assets
For SaaS companies, help centers and developer docs often contain the most precise, source-worthy content on the domain. They should be structured, canonicalized, maintained, and internally linked from marketing pages.
7. Keep freshness visible
If a page covers AI, law, finance, health, software, pricing, or anything that changes quickly, show when it was updated. Keep the actual passages current, not just the byline.
Three Examples
Example 1: SaaS pricing page
Before: A vague pricing page with “Contact us” buttons and benefit copy.
After: A pricing page with plan ranges, implementation fees, billing model, seat minimums, feature matrix, ideal customer profiles, limitations, FAQs, and migration notes.
Why it helps AI Search: It gives the answer engine structured passages for queries like “how much does X cost,” “is X good for startups,” “X alternatives,” and “X implementation cost.”
Example 2: Local service page
Before: “We are the best roofing company in Toronto.”
After: Service area, roof types, price ranges, permit considerations, seasonal issues, insurance notes, before/after examples, warranty terms, and common repair scenarios.
Why it helps AI Search: It supports locality, trust, and specific user context. It can answer “roof leak repair cost in Toronto,” “flat roof vs shingles Toronto,” and “emergency roof repair after storm.”
Example 3: Research article
Before: A long opinion essay with no source structure.
After: Abstract, thesis, methodology, evidence table, quoted sources, definitions, implications, and practical checklist.
Why it helps AI Search: It gives the model a clean evidence hierarchy. It can extract the thesis, cite the evidence, and summarize the implications.
AI Search Optimization Checklist
Use this as a working QA checklist for important pages.
- Can the page answer the primary query in two to four sentences?
- Can each major section stand alone?
- Are headings written as clear topics or questions?
- Are facts backed by visible evidence?
- Are dates, authors, and update history clear?
- Are entities named consistently?
- Are comparison criteria explicit?
- Does the page answer likely follow-up questions?
- Are sections internally linkable with stable anchors?
- Is important content present in the initial HTML?
- Are images and videos described with alt text, captions, and surrounding context?
- Does the page include original value that a generic AI answer cannot invent?
What Not To Overclaim
A warning: patents are not ranking-factor documentation. They are legal and technical documents that describe possible implementations. Google may use some, all, or none of a patented system in production. Production systems may also include layers not visible in the patents.
So the right conclusion is not “this patent proves the exact AI Overview algorithm.” The right conclusion is more practical: these patents reveal the shape of the problem Google is solving. Google needs AI answers that are useful, grounded, fast, attributable, personalized, and safe. Websites that make those jobs easier have an advantage.
Become The Page The Answer Engine Can Trust
The future of SEO is not tricking the answer engine. It is becoming the source the answer engine can safely use.
That means pages need to do more than rank. They need to answer cleanly, support claims, expose structure, identify entities, stay current, and provide original value. They need to be useful as documents, but also useful as source material.
The old SEO game rewarded the page that won the click. AI Search rewards the passage that earns trust. The winners will not be the loudest pages on the web. They will be the pages a machine can quote without embarrassment.
References
- US11769017B1 — Generative summaries for search results
- US11886828B1 — Generative summaries for search results
- US20240289407A1 — Search with stateful chat
- US20240289395A1 — Factuality of generated responses
- US12437016B2 — Fine-tuning large language model(s) using reinforcement learning with search engine feedback
- US20250117381A1 — Utilizing large language model (LLM) in responding to multifaceted queries
- US20240362093A1 — Query response using a custom corpus
- US20240311405A1 — Dynamic selection from among multiple candidate generative models with differing computational efficiencies
- US20240202796A1 — Search with Machine-Learned Model-Generated Queries
- WO2025072745A1 — Session-based user awareness in large language models
- US11947923B1 — Multimedia content management for large language model(s) and/or other generative model(s)
- US12266065B1 — Visual indicators of generative model response details